
Introduction
Source: Dataset
Project Type: Recommendation System
Problem: Implementation of recommendation system in the online shop platform has been able to increase sales as the user was provided by the product of their interest. Here is an example of the recommendation system that was built based on the preferences of other users that is called collaborative filtering.
Data Description
The dataset has 4 columns and 22.507.155 rows of books rated on amazon. The dataset contains information about user id, book id, rating, and timestamp.
import numpy as np
import pandas as pd
import sklearn
import matplotlib.pyplot as plt
import seaborn as snsdf = pd.read_csv("Dataset/amazon_book_rating.csv",header=None)
new_header = ['user','book_id','rating','timestamp']
df.columns = new_header
df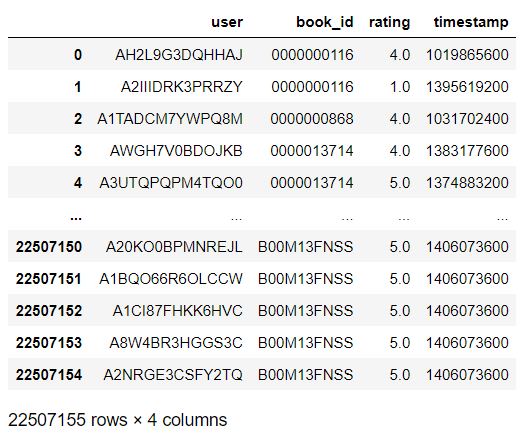
Find details about the dataset
print('Total Data')
print('-'*50)
print('Total Number of Ratings: ',df.shape[0])
print('Total Number of User: ',len(np.unique(df.user)))
print('Total Number of Books: ',len(np.unique(df.book_id)))Output: Total Data -------------------------------------------------- Total Number of Ratings: 22507155 Total Number of User: 8026324 Total Number of Books: 2330066
Plot a bar chart to have a better picture of the rating
num = sns.countplot(x='rating',data=df,palette='summer')
num.set(xlabel='Rating',ylabel='Total number of ratings')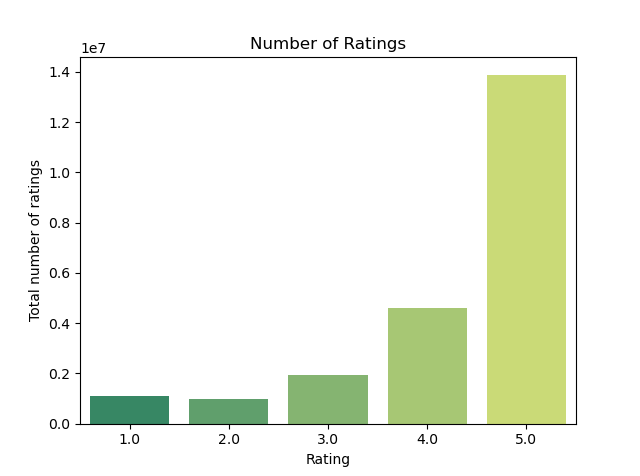
It can be seen that more than 60% of the users were given a 5.0 rating for the book they have purchased while the remains are divided into 4 other rangkings.
Data Preparation
Among the 4 columns provided, the timestamp column is not used in this project so it can be discarded.
df.drop(['timestamp'],axis=1,inplace=True)Then, calculate the average rating and the number of ratings received by each book.
books_ratings = pd.DataFrame(df.groupby(by='book_id')['rating'].mean())
books_ratings['num_of_ratings'] = df.groupby(by='book_id')['rating'].count()
book_rating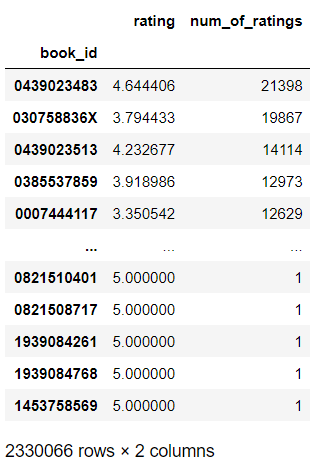
The result shows that there are 2.330.066 books in the record with the highest number of ratings of 21.398 and the lowest of 1. Because the number of books recorded is too much and the difference between the most and least book rated is too far, the dataset will be filtered for books with the minimum number of ratings of 1000.
filter_by_ratings = books_ratings.loc[books_ratings['num_of_ratings'] > 1000].sort_values(by='num_of_ratings',ascending=False)
filter_by_ratings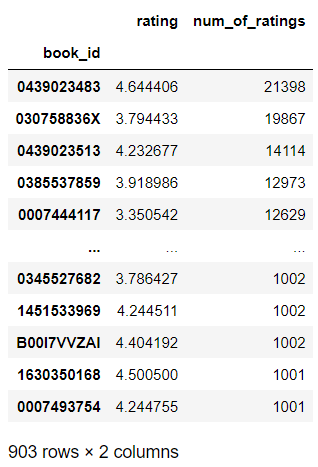
Thus, 903 books were obtained and would be used to create a recommendation system. Let’s create a new data frame with the filtered book id.
filtered_book_id = filter_by_ratings.index.tolist()df_new = df[df['book_id'].isin(filtered_book_id)]
df_newThis illustrates one of the disadvantages of the collaborative filtering method where a product will only be recommended if it already has enough rating.
Create a pivot table to present the rating score given by each user to all books. If there is no rating given, the score is 0.
book_mat = df_new.pivot_table(index='user',columns='book_id',values='rating').fillna(0)
book_mat
rated_book_id = '1630350168'
rated_book_ratings = book_mat[rated_book_id]
rated_book_ratings
Item-based without Machine Learnine
similar_book_rated = book_mat.corrwith(rated_book_ratings)
df_book_corr = pd.DataFrame(similar_book_rated,columns=['correlation'])
df_book_corr = df_book_corr.join(books_ratings['num_of_ratings'])book_recommendation = df_book_corr.sort_values(by='correlation', ascending=False).iloc[1:].head(10)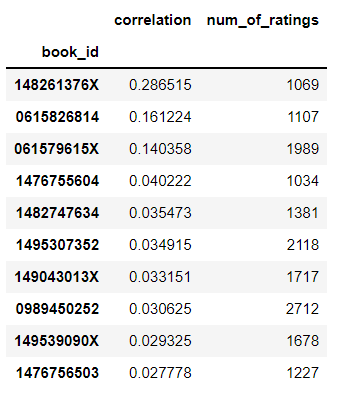
Item-based by KNNWithMeans
import surprise
from surprise import KNNWithMeans
from surprise import Dataset
from surprise import Reader
from surprise.model_selection import train_test_split
from surprise import accuracyreader = Reader(rating_scale=(1, 5))
data = Dataset.load_from_df(df_new,reader)Split data for training and testing.
trainset, testset = train_test_split(data, test_size=0.3)Train the model of KNNWithMeans with a k-value of 5.
model = KNNWithMeans(k=5,sim_options={'name': 'pearson_baseline', 'user_based': False})
model.fit(trainset)Test the model with data for testing.
test_pred = model.test(testset)print("Item-based Model : Test Set")
accuracy.rmse(test_pred, verbose=True)Output: Item-based Model : Test Set RMSE: 1.1336 1.133583609139205
book_mat_t = book_mat.T
book_mat_t
from sklearn.decomposition import TruncatedSVD
SVD = TruncatedSVD(n_components=10)
decomposed_matrix = SVD.fit_transform(book_mat_t)
decomposed_matrix.shapecorrelation_matrix = np.corrcoef(decomposed_matrix)
correlation_matrix.shaperated_book_id = '1630350168'Get index for book_id 1630350168
all_books = list(book_mat_t.index)
rated_book_index = all_books.index(rated_book_id)Calculate the correlation of the book with other books
correlation_book = correlation_matrix[rated_book_index]Filter the result for books with correlation more than 0.7 and remove the book from list
book_recommendation_2 = list(book_mat_t.index[correlation_book > 0.7])
book_recommendation_2.remove(rated_book_id)
book_recommendation_2Choose 10 books randomly because from the results of recommendations there are more than 10 books recommended
import random
random.sample(book_recommendation_2, 10)Output: ['014219672X','1461052149','1469982781' ,'061579615X','0989450236','1476763526' ,'1451533969','1455578312','1612186009' ,'1476755590']
Conclusion
A recommendation system based on the KNNWithMeans model shows reliability compared to non-machine learning modeling, according to the correlation scores obtained. The maximum correlation score for a recommendation system without ML is obtained less than 0.3 whereas if with AI the recommendation can be filtered with a correlation of at least 0.7.
